
Chúng tôi đã viết khá nhiều lần về ảnh hưởng của gió đến ô nhiễm không khí và gió mạnh (hay nói chính xác hơn là thông gió mạnh) có thể giúp làm sạch không khí trong thời gian rất ngắn như thế nào. Nhưng chúng tôi chưa bao giờ có cơ hội tạo ra một hình ảnh trực quan sinh động về hiện tượng này, vì vậy đây chính là nội dung mà bài viết này sẽ viết về.
--
Khi nói đến dự báo Chất lượng không khí, chìa khóa để có độ chính xác cao hơn là cải tiến mô hình dự báo và tạo ra mô hình hóa cụ thể cho từng quốc gia và thậm chí tốt hơn cho từng thành phố. Ví dụ, ở Bắc Kinh, sự gần gũi của các ngọn núi ở phía Bắc và Hà Bắc ở phía Nam đã xác định mô hình:
- Gió nam có xu hướng làm tăng ô nhiễm ở Bắc Kinh: Nếu gió không đủ mạnh (tức là không đủ thông gió ) thì các hạt sẽ bị núi chặn lại và không thể di chuyển xa hơn về phía bắc, từ đó tạo ra các hạt dày đặc tập trung ở Bắc Kinh.
- Gió Bắc có xu hướng làm sạch ô nhiễm: Khi gió Bắc thổi đủ mạnh, không khí gần như được làm sạch ngay lập tức do không có “nguồn ô nhiễm” nào ở phía Bắc (hoặc ít nhất là ít hơn nhiều so với phía Nam).
Đây là những gì người ta có thể thấy trong hình ảnh động bên dưới, trong đó các nguồn ô nhiễm được đặt tùy ý tại các trạm quan trắc ở Hà Bắc. Mỗi nguồn ô nhiễm phát ra một hạt mỗi giờ. Số lượng hạt trong một vùng càng nhiều thì mức độ ô nhiễm càng cao (màu xanh tương ứng với nồng độ thấp, màu đỏ ~ nâu tương ứng với nồng độ cao). Mô hình gió dựa trên Hệ thống dự báo toàn cầu (còn gọi là GFS).
--
version 1.2 (2016/2/18)
--
Tất nhiên đây là một mô hình rất nhẹ so với các mô hình phức tạp đòi hỏi sức mạnh xử lý siêu máy tính để có thể tính toán dự báo chất lượng không khí trên toàn thế giới. Nhưng nó có ưu điểm là giải thích trực quan khái niệm cơ bản đằng sau việc dự báo chất lượng không khí.
Nói chính xác hơn, mô hình nên bao gồm cấu hình gió thẳng đứng, cũng như dự báo cho một số độ cao (lớp) - hiện tại, mô hình chỉ sử dụng dự báo ở độ cao 10 mét, 100 mét và 5KM. Hơn nữa, các nguồn ô nhiễm cần phải đầy đủ hơn và bao gồm các nguồn tổng thể trên thế giới - hiện tại chỉ bao gồm các nguồn từ Hà Bắc.
--
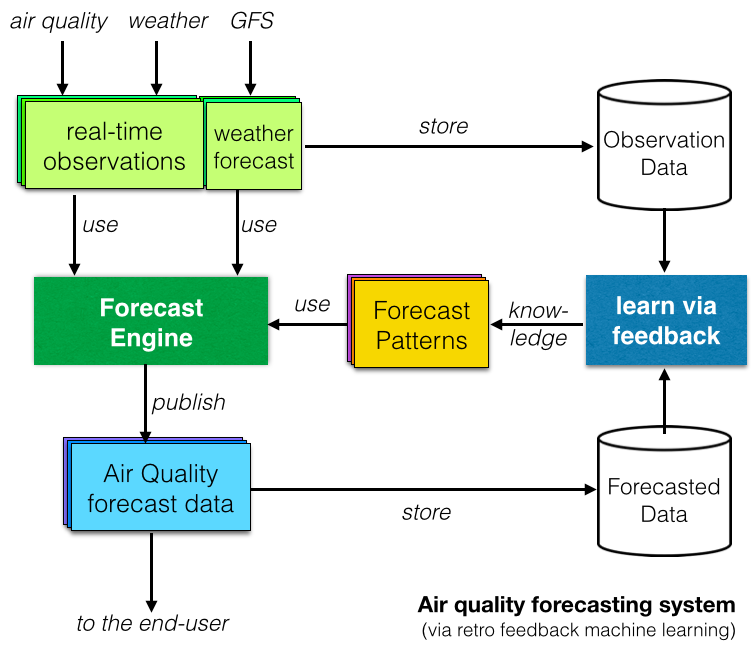
Cuối cùng, nhiều báo cáo nghiên cứu đã điều tra các hệ thống dự báo Chất lượng không khí dựa trên Machine Learning hoặc Trí tuệ nhân tạo . Khái niệm đằng sau là "tìm hiểu" bằng cách so sánh dữ liệu được quan sát với dữ liệu dự báo và xác định các mẫu lặp lại (như được hiển thị trên sơ đồ bên phải).
Trên giấy tờ, hệ thống dự báo dựa trên Machine Learning có vẻ tốt, nhưng trên thực tế, chúng có tốt hơn các mô hình xác định truyền thống (mà chúng tôi thích ở dự án Chỉ số chất lượng không khí thế giới ) không? Đề cập đến bài nói chuyện TED xuất sắc của Talithia Williams về 'Sở hữu dữ liệu cơ thể của bạn', câu trả lời của chúng tôi cho câu hỏi này là "cho chúng tôi xem dữ liệu!", và đó là điều chúng tôi sẽ viết trong bài viết tiếp theo về dự báo!
