
เราได้เขียนมาหลายครั้งแล้วเกี่ยวกับอิทธิพลของลมที่มีต่อมลพิษทางอากาศ และลมแรง (หรือถ้าให้พูดให้ละเอียดกว่านั้นคือ การระบายอากาศ ที่แรง) สามารถช่วยทำความสะอาดอากาศได้ในเวลาอันสั้นเพียงใด แต่เราไม่เคยมีโอกาสสร้างภาพแบบไดนามิกของปรากฏการณ์นี้ ดังนั้นนี่คือสิ่งที่บทความนี้จะเขียน
--
เมื่อพูดถึงการคาดการณ์คุณภาพอากาศ กุญแจสำคัญสู่ความแม่นยำที่ดีขึ้นคือการปรับปรุงโมเดลการคาดการณ์ และสร้างแบบจำลองเฉพาะสำหรับแต่ละประเทศ และที่ดียิ่งขึ้นสำหรับแต่ละเมือง ตัวอย่างเช่น ในกรุงปักกิ่ง ใกล้กับภูเขาทางตอนเหนือและเหอเป่ยทางใต้ ซึ่งเป็นตัวกำหนดแบบจำลอง:
- ลมใต้มีแนวโน้มที่จะเพิ่มมลพิษในกรุงปักกิ่ง หากลมไม่แรงพอ (เช่น การระบายอากาศ ไม่เพียงพอ) อนุภาคจะถูกภูเขาบังและไม่สามารถเคลื่อนตัวไปทางเหนือได้อีกจึงทำให้เกิดอนุภาคหนาแน่น ความเข้มข้นในกรุงปักกิ่ง
- ลมเหนือมีแนวโน้มที่จะช่วยขจัดมลพิษ: เมื่อลมพัดมาจากทางเหนืออย่างเพียงพอ อากาศจะปลอดโปร่งเกือบจะในทันทีเนื่องจากไม่มี "แหล่งกำเนิดมลพิษ" ในภาคเหนือ (หรืออย่างน้อยก็น้อยกว่าทางใต้มาก)
นี่คือสิ่งที่เราเห็นได้ในภาพเคลื่อนไหวด้านล่าง ซึ่งแหล่งที่มาของมลภาวะนั้นตั้งอยู่ตามอำเภอใจ โดยที่สถานีตรวจสอบตั้งอยู่ในเหอเป่ย แหล่งกำเนิดมลพิษแต่ละแห่งจะปล่อยอนุภาคหนึ่งอนุภาคทุกๆ ชั่วโมง ยิ่งจำนวนอนุภาคในโซนเพิ่มมากขึ้น มลพิษก็จะยิ่งสูงขึ้น (สีน้ำเงินหมายถึงความเข้มข้นต่ำ สีแดง ~ สีน้ำตาลถึงความเข้มข้นสูง) แบบจำลองลมอิงตามระบบพยากรณ์ทั่วโลก (หรือที่เรียกว่า GFS)
--
version 1.2 (2016/2/18)
--
แน่นอนว่านี่เป็นโมเดลที่เบามากเมื่อเทียบกับโมเดลที่ซับซ้อนซึ่งต้องใช้พลังการประมวลผลของซูเปอร์คอมพิวเตอร์เพื่อให้สามารถคำนวณการคาดการณ์คุณภาพอากาศทั่วโลกได้ แต่มีข้อได้เปรียบในการอธิบายแนวคิดพื้นฐานเบื้องหลังการพยากรณ์คุณภาพอากาศด้วยภาพ
เพื่อให้แม่นยำยิ่งขึ้น แบบจำลองควรมีโปรไฟล์ลมในแนวตั้ง รวมถึงการพยากรณ์ความสูง (ชั้น) หลายระดับ - ขณะนี้แบบจำลองใช้การพยากรณ์ที่ 10 เมตร 100 เมตร และ 5 กม. เท่านั้น นอกจากนี้ แหล่งที่มาของมลพิษควรมีความสมบูรณ์มากขึ้นและรวมถึงแหล่งที่มาของโลกโดยรวมด้วย โดยปัจจุบันรวมเฉพาะแหล่งที่มาจากเหอเป่ยเท่านั้น
--
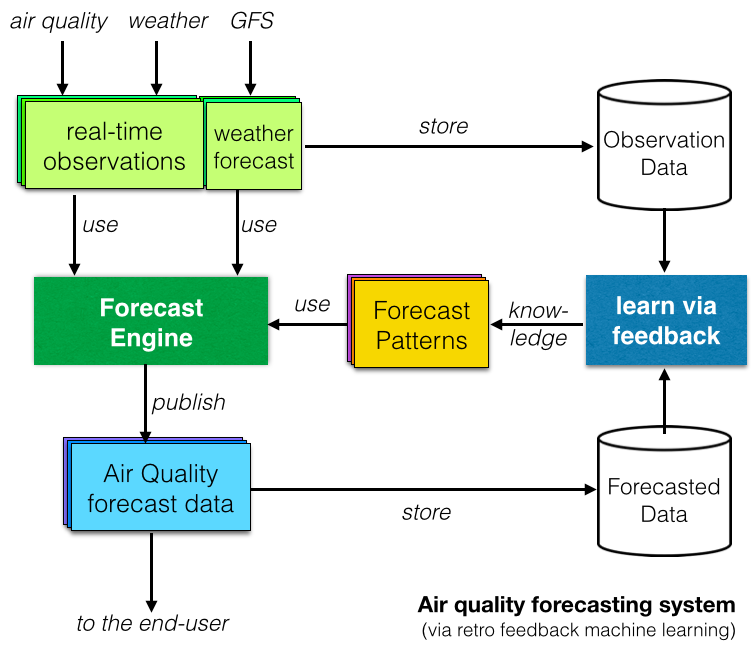
สุดท้าย รายงานการวิจัยจำนวนมากได้ตรวจสอบระบบพยากรณ์คุณภาพอากาศด้วย การเรียนรู้ของเครื่อง หรือ ปัญญาประดิษฐ์ แนวคิดเบื้องหลังคือการ "เรียนรู้" โดยการเปรียบเทียบข้อมูลที่สังเกตได้กับข้อมูลที่คาดการณ์ และระบุรูปแบบที่ซ้ำกัน (ดังแสดงในแผนภาพด้านขวา)
ในรายงาน ระบบพยากรณ์ด้วยการเรียนรู้ของเครื่องดูดี แต่ในความเป็นจริงแล้ว สิ่งเหล่านี้ดีกว่าแบบจำลองที่กำหนดแบบดั้งเดิม (ซึ่งเราชอบใน โครงการดัชนีคุณภาพอากาศโลก มากกว่า) หรือไม่ จากการพูด คุยที่ยอดเยี่ยมของ TED จาก Talithia Williams ในหัวข้อ 'เป็นเจ้าของข้อมูลร่างกายของคุณ' คำตอบของเราสำหรับคำถามนี้คือ "แสดงข้อมูลให้เราดู!" และนั่นคือสิ่งที่เราจะเขียนถึงในบทความถัดไปเกี่ยวกับการพยากรณ์!

