
हम वायु प्रदूषण पर हवा के प्रभाव के बारे में कई बार लिखते रहे हैं, और कैसे तेज हवाएं (या, अधिक सटीक रूप से कहें तो, मजबूत वेंटिलेशन ) बहुत कम समय में हवा को साफ करने में मदद कर सकती हैं। लेकिन हमें कभी भी इस घटना का गतिशील दृश्य बनाने का अवसर नहीं मिला, इसलिए यह लेख इसी बारे में लिखेगा।
--
जब वायु गुणवत्ता पूर्वानुमान की बात आती है, तो बेहतर सटीकता की कुंजी पूर्वानुमान मॉडल को परिष्कृत करना है, और प्रत्येक देश के लिए एक विशिष्ट मॉडल तैयार करना है, और, प्रत्येक शहर के लिए और भी बेहतर है। उदाहरण के लिए, बीजिंग में, यह उत्तर में पहाड़ों और दक्षिण में हेबेई की निकटता है जो मॉडल को परिभाषित करती है:
- दक्षिणी हवा बीजिंग में प्रदूषण को बढ़ाती है: यदि हवा पर्याप्त तेज़ नहीं है (यानी पर्याप्त हवादार नहीं है), तो कण पहाड़ों से अवरुद्ध हो जाएंगे और उत्तर की ओर आगे नहीं बढ़ पाएंगे, इस प्रकार घने कण बनेंगे बीजिंग में एकाग्रता
- उत्तरी हवाएँ प्रदूषण को साफ़ करती हैं: जब हवाएँ उत्तर से पर्याप्त मात्रा में चलती हैं, तो हवा लगभग तुरंत साफ़ हो जाती है क्योंकि उत्तर में कोई "प्रदूषण स्रोत" नहीं है (या, कम से कम, दक्षिण की तुलना में बहुत कम)।
इसे नीचे दिए गए एनीमेशन में देखा जा सकता है, जिसमें प्रदूषण स्रोत मनमाने ढंग से स्थित हैं जहां हेबै में निगरानी स्टेशन स्थित हैं। प्रत्येक प्रदूषण स्रोत हर घंटे एक कण उत्सर्जित करता है। किसी क्षेत्र में कणों की संख्या जितनी अधिक होगी, प्रदूषण उतना ही अधिक होगा (नीला कम सांद्रता, लाल ~ भूरा उच्च सांद्रता से मेल खाता है)। पवन मॉडल वैश्विक पूर्वानुमान प्रणाली (उर्फ जीएफएस) पर आधारित है।
--
version 1.2 (2016/2/18)
--
यह निश्चित रूप से उन जटिल मॉडलों की तुलना में बहुत हल्का मॉडल है, जिन्हें पूरी दुनिया की वायु गुणवत्ता पूर्वानुमान की गणना करने में सक्षम होने के लिए सुपर कंप्यूटर प्रोसेसिंग पावर की आवश्यकता होती है। लेकिन इसमें वायु गुणवत्ता पूर्वानुमान के पीछे की मूल अवधारणा को स्पष्ट रूप से समझाने का लाभ है।
अधिक सटीक होने के लिए, मॉडल में ऊर्ध्वाधर पवन प्रोफ़ाइल, साथ ही कई ऊंचाइयों (परतों) के लिए पूर्वानुमान शामिल होना चाहिए - वर्तमान में, मॉडल केवल 10 मीटर, 100 मीटर और 5KM पर पूर्वानुमान का उपयोग कर रहा है। इसके अलावा, प्रदूषण स्रोत अधिक संपूर्ण होने चाहिए और इसमें समग्र विश्व स्रोत शामिल होने चाहिए - वर्तमान में, केवल हेबै के स्रोत शामिल हैं।
--
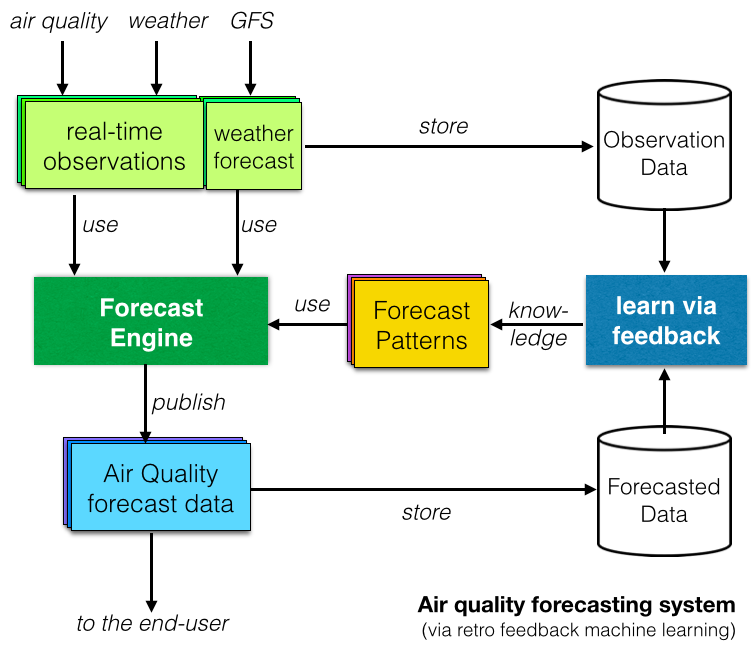
अंत में, कई शोध रिपोर्टों ने मशीन लर्निंग या आर्टिफिशियल इंटेलिजेंस आधारित वायु गुणवत्ता पूर्वानुमान प्रणालियों की जांच की है। इसके पीछे की अवधारणा पूर्वानुमानित डेटा के साथ देखे गए डेटा की तुलना करके "सीखना" है और दोहराव वाले पैटर्न की पहचान करना है (जैसा कि दाईं ओर चित्र में दिखाया गया है)।
कागज पर, मशीन लर्निंग आधारित पूर्वानुमान प्रणाली अच्छी लगती है, लेकिन वास्तव में, क्या वे पारंपरिक नियतात्मक मॉडल (जिसे हम विश्व वायु गुणवत्ता सूचकांक परियोजना में पसंद करते हैं) से बेहतर हैं? 'अपने शरीर के डेटा का मालिक बनें' पर टैलिथिया विलियम्स की उत्कृष्ट TED वार्ता का संदर्भ लेते हुए, इस प्रश्न का हमारा उत्तर है "हमें डेटा दिखाएं!", और यह कुछ ऐसा है जिसके बारे में हम पूर्वानुमान पर अपने अगले लेख में लिखेंगे!

