
私たちは、大気汚染に対する風の影響と、強風 (より正確に言えば、強力な換気) がいかに短時間で空気を浄化するのに役立つかについて、何度も書いてきました。しかし、この現象の動的な視覚化を作成する機会がなかったので、これがこの記事の内容です。
--
大気質予測に関して言えば、精度を高める鍵となるのは、予測モデルを改良し、各国、さらには都市ごとに特定のモデル化を作成することです。たとえば、北京では、北の山と南の河北省が近いことがモデルを定義します。
- 南風は北京の汚染を増加させる傾向があります。風が十分に強くない(つまり、換気が十分でない)場合、粒子は山によってブロックされ、さらに北へ移動できなくなり、高密度の粒子が生成されます。北京に集中。
- 北風は汚染を除去する傾向があります。北からの風が十分に吹くと、北には「汚染源」が存在しない(または、少なくとも南部よりもはるかに少ない)ため、空気はほぼ即座に浄化されます。
これは以下のアニメーションで見ることができるもので、河北省の監視ステーションが設置されている場所に汚染源が恣意的に配置されています。各汚染源は 1 時間ごとに 1 つの粒子を放出します。ゾーン内の粒子の数が多いほど、汚染度は高くなります(青は低濃度、赤〜茶色は高濃度に対応します)。風力モデルは、Global Forecast System (別名 GFS) に基づいています。
--
version 1.2 (2016/2/18)
--
もちろん、これは、全世界の大気質予測を計算するためにスーパー コンピューターの処理能力を必要とする複雑なモデルと比較すると、非常に軽量なモデルです。ただし、大気質予測の背後にある基本概念を視覚的に説明できるという利点があります。
より正確には、モデルには垂直風プロファイルといくつかの高さ (レイヤー) の予測が含まれている必要があります。現在、モデルは高度 10 メートル、100 メートル、および 5KM での予測のみを使用しています。さらに、汚染源はより完全なものであり、世界全体の発生源が含まれている必要があります。現在、河北省からの発生源のみが含まれています。
--
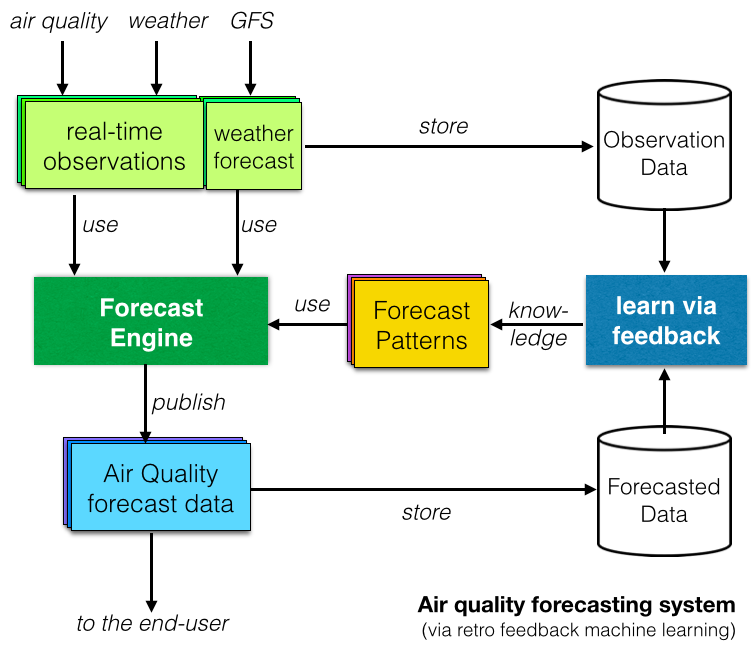
最後に、多くの研究レポートでは、機械学習または人工知能ベースの大気質予測システムが調査されています。背後にある概念は、観測データと予測データを比較し、反復パターンを特定することで「学習」することです (右の図を参照)。
机上では、機械学習ベースの予測システムは優れているように見えますが、実際には、従来の決定論的モデル (世界大気質指数プロジェクトではこのモデルを好んでいます) よりも優れているのでしょうか?タリシア・ウィリアムズによる「自分の体のデータを自分のものにする」に関する優れたTED トークを参照すると、この質問に対する私たちの答えは「データを見せてください!」です。これについては、予測に関する次回の記事で書く予定です。

