
Мы уже не раз писали о влиянии ветра на загрязнение воздуха и о том, как сильный ветер (или, если быть точнее, сильная вентиляция ) может помочь очистить воздух за очень короткое время. Но у нас никогда не было возможности создать динамическую визуализацию этого явления, поэтому именно об этом и пойдет речь в этой статье.
--
Когда дело доходит до прогнозирования качества воздуха, ключом к большей точности является уточнение модели прогнозирования и создание конкретной модели для каждой страны и, что еще лучше, для каждого города. Например, в Пекине модель определяется близостью гор на севере и Хэбэя на юге:
- Южный ветер имеет тенденцию увеличивать загрязнение в Пекине: если ветер недостаточно сильный (т.е. недостаточно вентилируется ), то частицы будут заблокированы горами и не смогут двигаться дальше на север, создавая таким образом плотные частицы. концентрация в Пекине.
- Северный ветер имеет тенденцию очищать загрязнения: когда ветер достаточно сильно дует с севера, воздух почти сразу очищается, поскольку на севере нет «источника загрязнения» (или, по крайней мере, гораздо меньше, чем на юге).
Это то, что можно увидеть на анимации ниже, на которой источники загрязнения произвольно расположены там, где расположены станции мониторинга в Хэбэе. Каждый источник загрязнения выбрасывает одну частицу каждый час. Чем больше частиц в зоне, тем выше загрязнение (синий цвет соответствует низкой концентрации, красный ~ коричневый — высокой концентрации). Модель ветра основана на Глобальной системе прогнозов (также известной как GFS).
--
version 1.2 (2016/2/18)
--
Это, конечно, очень легкая модель по сравнению со сложными моделями, которые требуют вычислительной мощности суперкомпьютера для расчета прогноза качества воздуха во всем мире. Но у него есть то преимущество, что он наглядно объясняет основную концепцию прогнозирования качества воздуха.
Точнее, модель должна включать вертикальный профиль ветра, а также прогноз для нескольких высот (слоев) — в настоящее время модель использует прогноз только на 10 метров, 100 метров и 5 км. Более того, источники загрязнения должны быть более полными и включать в себя все мировые источники - в настоящее время включены только источники из провинции Хэбэй.
--
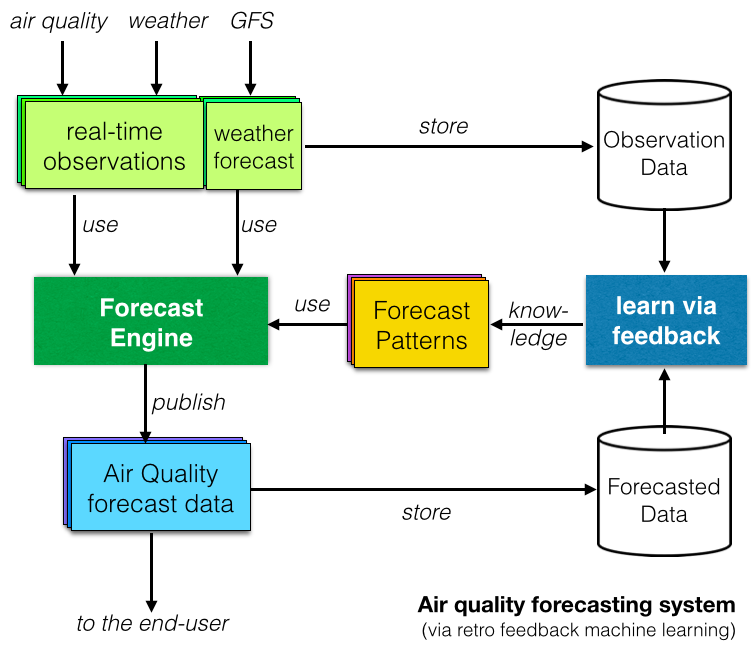
Наконец, во многих исследовательских отчетах изучались системы прогнозирования качества воздуха на основе машинного обучения или искусственного интеллекта . Идея заключается в том, чтобы «обучиться» путем сравнения наблюдаемых данных с прогнозируемыми данными и выявить повторяющиеся закономерности (как показано на диаграмме справа).
На бумаге системы прогнозирования, основанные на машинном обучении, выглядят хорошо, но на самом деле, лучше ли они, чем традиционные детерминистические модели (которые мы предпочитаем в проекте World Air Quality Index )? Ссылаясь на превосходное выступление Талитии Уильямс на TED на тему «Владейте данными своего тела», наш ответ на этот вопрос — «покажите нам данные!», и об этом мы напишем в нашей следующей статье о прогнозировании!

