
Писали смо доста пута о утицају ветра на загађење ваздуха и о томе како јаки ветрови (или, тачније, јака вентилација ) могу помоћи да се ваздух очисти за врло кратко време. Али никада нисмо имали прилику да стварамо на динамичкој визуелизацији овог феномена, па ће о томе писати овај чланак.
--
Када је у питању предвиђање квалитета ваздуха, кључ за бољу тачност је пречишћавање модела прогнозе и креирање специфичне моделизације за сваку земљу, и, још боље, за сваки град. На пример, у Пекингу је близина планина на северу и Хебеија на југу оно што дефинише модел:
- Јужни ветар има тенденцију да повећа загађење у Пекингу: Ако ветар није довољно јак (тј. не вентилира довољно), онда ће честице бити блокиране од стране планина и неће моћи да се крећу даље ка северу, стварајући тако густу честицу концентрација у Пекингу.
- Северни ветар има тенденцију да очисти загађење: Када ветар довољно дува са севера, ваздух се скоро одмах чисти пошто на северу нема „извора загађења“ (или, барем, много мање него на југу).
Ово се може видети у анимацији испод, у којој су извори загађења произвољно лоцирани тамо где се налазе станице за праћење у Хебеију. Сваки извор загађења емитује једну честицу сваког сата. Што је већи број честица у зони, веће је загађење (плаво одговара ниској концентрацији, црвено ~ браон високим концентрацијама). Модел ветра је заснован на Глобалном систему прогнозе (ака ГФС).
--
version 1.2 (2016/2/18)
--
Ово је наравно веома лаган модел у поређењу са сложеним моделима који захтевају супер рачунарску процесорску снагу да би могли да израчунају прогнозу квалитета ваздуха у целом свету. Али има предност што визуелно објашњава основни концепт који стоји иза предвиђања квалитета ваздуха.
Да будемо прецизнији, модел треба да садржи вертикални профил ветра, као и прогнозу за неколико висина (слојева) - тренутно модел користи само прогнозу на 10 метара, 100 метара и 5КМ. Штавише, извори загађења треба да буду потпунији и да обухватају свеукупне светске изворе – тренутно су укључени само извори из Хебеија.
--
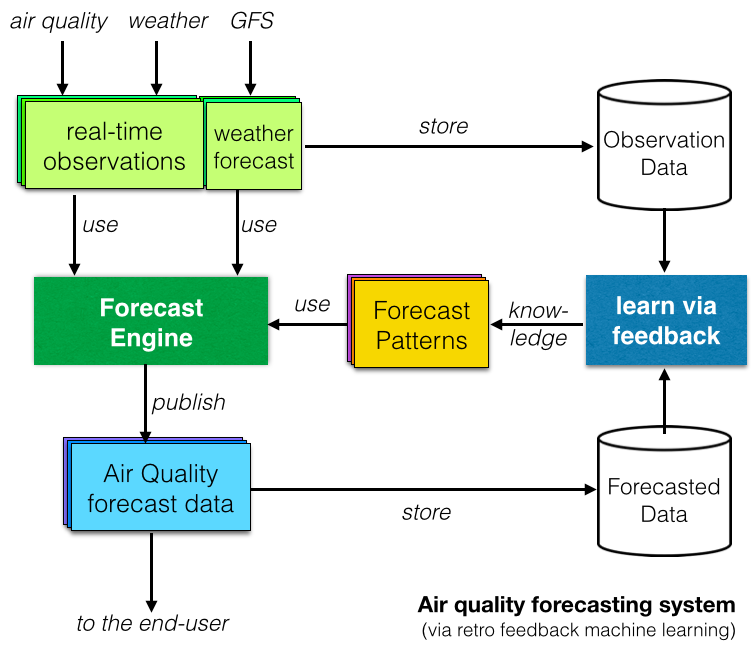
На крају, многи истраживачки извештаји су истраживали системе за предвиђање квалитета ваздуха засноване на машинском учењу или вештачкој интелигенцији . Концепт иза је да се „учи“ упоређивањем посматраних података са прогнозираним подацима и идентификацијом понављајућих образаца (као што је приказано на дијаграму са десне стране).
На папиру, систем предвиђања заснован на машинском учењу изгледа добро, али у ствари, да ли су они бољи од традиционалних детерминистичких модела (које преферирамо у пројекту Светског индекса квалитета ваздуха )? Позивајући се на одличан ТЕД говор Талитије Вилијамс о „Поседујте податке свог тела“, наш одговор на ово питање је „покажите нам податке!“, и то је нешто о чему ћемо писати у нашем следећем чланку о предвиђању!

