
Jó néhányszor írtunk már arról, hogy a szél milyen hatással van a légszennyezésre, és hogy az erős szél (pontosabban az erős szellőzés ) hogyan segíthet a levegő nagyon rövid időn belüli megtisztításában. De soha nem volt lehetőségünk a jelenség dinamikus megjelenítésére alkotni, ezért ez a cikk erről fog írni.
--
Amikor a levegőminőség előrejelzéséről van szó, a jobb pontosság kulcsa az előrejelzési modell finomítása, valamint egy egyedi modell létrehozása minden országhoz, és még jobb, ha minden városhoz. Például Pekingben az északi hegyek és a déli Hebei közelsége határozza meg a modellt:
- A déli szél növeli a szennyezést Pekingben: Ha a szél nem elég erős (azaz nem szellőztet eléggé), akkor a részecskéket a hegyek elzárják, és nem tudnak tovább mozogni észak felé, így sűrű részecske jön létre. koncentráció Pekingben.
- Az északi szél általában megtisztítja a szennyezést: Ha elegendő északi szél fúj, a levegő szinte azonnal kitisztul, mivel északon nincs "szennyezőforrás" (vagy legalábbis sokkal kevesebb, mint délen).
Ez látható az alábbi animáción, amelyben a szennyező források tetszőlegesen ott helyezkednek el, ahol a monitoring állomások találhatók Hebeiben. Minden szennyezőforrás óránként egy részecskét bocsát ki. Minél több a részecskék száma egy zónában, annál nagyobb a szennyezés (a kék az alacsony koncentrációnak, a piros ~ barna a magas koncentrációnak felel meg). A szélmodell a Global Forecast System-en (más néven GFS) alapul.
--
version 1.2 (2016/2/18)
--
Ez természetesen nagyon könnyű modell azokhoz az összetett modellekhez képest, amelyek szuperszámítógépes feldolgozási teljesítményt igényelnek ahhoz, hogy ki tudják számítani az egész világ levegőminőségi előrejelzését. De megvan az az előnye, hogy vizuálisan elmagyarázza a levegőminőség-előrejelzés mögötti alapkoncepciót.
Pontosabban, a modellnek tartalmaznia kell a függőleges szélprofilt, valamint a több magasságra (rétegre) vonatkozó előrejelzést – jelenleg a modell csak 10 méteres, 100 méteres és 5 km-es előrejelzést használ. Sőt, a szennyező forrásoknak teljesebbnek kell lenniük, és magukban kell foglalniuk a világ teljes forrásait – jelenleg csak a Hebeiből származó források szerepelnek.
--
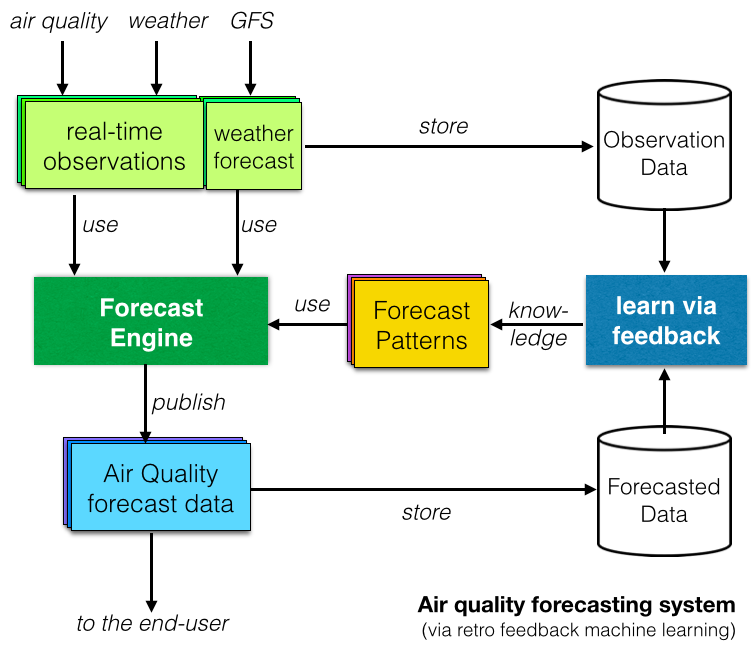
Végül számos kutatási jelentés vizsgálta a gépi tanuláson vagy a mesterséges intelligencián alapuló levegőminőség-előrejelző rendszereket. A mögöttes koncepció a „tanulás” a megfigyelt adatok és az előrejelzett adatok összehasonlításával, és az ismétlődő minták azonosítása (ahogyan a jobb oldali diagramon látható).
Papíron a Machine Learning alapú előrejelző rendszer jól néz ki, de valójában jobbak a hagyományos determinisztikus modelleknél (amelyeket a World Air Quality Index projektben preferálunk)? Hivatkozva Talithia Williams kiváló TED-előadására a „Tudja saját teste adatait” címmel, erre a kérdésre a válaszunk az, hogy „mutassa meg nekünk az adatokat!”, és erről fogunk írni az előrejelzésről szóló következő cikkünkben!

