
ما چندین بار در مورد تأثیر باد بر آلودگی هوا و اینکه چگونه بادهای قوی (یا به عبارت دقیق تر، تهویه قوی) می تواند به تمیز کردن هوا در مدت زمان بسیار کوتاه کمک کند، نوشته ایم. اما ما هرگز فرصتی برای ایجاد تجسم پویا از این پدیده نداشتیم، بنابراین این چیزی است که این مقاله درباره آن خواهد نوشت.
--
وقتی نوبت به پیشبینی کیفیت هوا میرسد، کلید دقت بهتر، اصلاح مدل پیشبینی و ایجاد یک مدلسازی خاص برای هر کشور، و حتی بهتر، برای هر شهر است. برای مثال، در پکن، نزدیکی کوهها در شمال و هبی در جنوب است که مدل را تعریف میکند:
- باد جنوبی تمایل به افزایش آلودگی در پکن دارد: اگر باد به اندازه کافی قوی نباشد (یعنی تهویه کافی نداشته باشد)، آنگاه ذرات توسط کوهها مسدود میشوند و نمیتوانند بیشتر به سمت شمال حرکت کنند و در نتیجه ذرات متراکمی ایجاد میکنند. تمرکز در پکن
- باد شمالی تمایل به پاکسازی آلودگی دارد: هنگامی که باد به اندازه کافی از شمال می وزد، هوا تقریباً بلافاصله پاک می شود زیرا هیچ "منبع آلودگی" در شمال (یا حداقل، بسیار کمتر از جنوب) وجود ندارد.
این چیزی است که می توانید در انیمیشن زیر مشاهده کنید که در آن منابع آلودگی به طور خودسرانه در جایی که ایستگاه های نظارتی در هبی واقع شده اند قرار گرفته اند. هر منبع آلودگی در هر ساعت یک ذره منتشر می کند. هرچه تعداد ذرات در یک منطقه بیشتر باشد، آلودگی بیشتر است (آبی مربوط به غلظت کم، قرمز ~ قهوه ای به غلظت بالا است). مدل باد بر اساس سیستم پیش بینی جهانی (معروف به GFS) است.
--
version 1.2 (2016/2/18)
--
البته این یک مدل بسیار سبک در مقایسه با مدلهای پیچیده است که به قدرت پردازش فوقالعاده کامپیوتری نیاز دارند تا بتوانند کل پیشبینی کیفیت هوای جهان را محاسبه کنند. اما این مزیت را دارد که مفهوم اساسی پیش بینی کیفیت هوا را به صورت بصری توضیح دهد.
به طور دقیق تر، مدل باید شامل مشخصات باد عمودی و همچنین پیش بینی چندین ارتفاع (لایه) باشد - در حال حاضر، مدل فقط از پیش بینی در 10 متر، 100 متر و 5 کیلومتر استفاده می کند. علاوه بر این، منابع آلودگی باید کامل تر باشد و منابع کلی جهان را در بر گیرد - در حال حاضر، فقط منابع هبی گنجانده شده است.
--
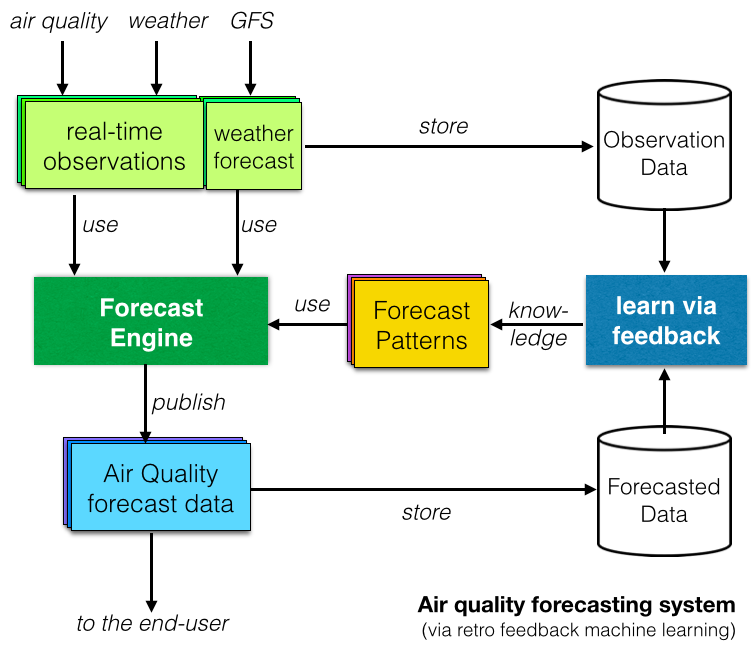
در نهایت، بسیاری از گزارشهای تحقیقاتی سیستمهای پیشبینی کیفیت هوا مبتنی بر یادگیری ماشین یا هوش مصنوعی را بررسی کردهاند. مفهوم پشت آن «یادگیری» با مقایسه داده های مشاهده شده با داده های پیش بینی شده و شناسایی الگوهای تکراری است (همانطور که در نمودار سمت راست نشان داده شده است).
روی کاغذ، سیستم پیشبینی مبتنی بر یادگیری ماشین خوب به نظر میرسد، اما در واقع، آیا آنها بهتر از مدلهای قطعی سنتی (که ما در پروژه شاخص کیفیت هوای جهانی ترجیح میدهیم) بهتر هستند؟ با اشاره به سخنرانی عالی TED از تالیثیا ویلیامز در مورد "داده های بدن خود را داشته باشید"، پاسخ ما به این سوال این است که "داده ها را به ما نشان دهید!"، و این چیزی است که در مقاله بعدی خود در مورد پیش بینی درباره آن خواهیم نوشت!

