
我們已經寫過好幾次關於風對空氣污染的影響,以及強風(或更準確地說,強通風)如何有助於在很短的時間內淨化空氣。但我們從未有機會創建這種現象的動態視覺化,所以這就是本文將要寫的內容。
--
在空氣品質預測方面,提高準確性的關鍵是完善預測模型,並為每個國家、甚至每個城市創建特定的模型。例如,在北京,北部的山脈和南部的河北的接近度定義了這個模型:
- 南風往往會加劇北京的污染:如果風不夠強(即通風不夠),那麼顆粒物就會被山脈阻擋,無法進一步向北移動,從而形成密集的顆粒物集中在北京。
- 北風往往能清除污染:當北風充分吹來時,空氣幾乎立即被清除,因為北方沒有「污染源」(或至少比南方少得多)。
如下動畫所示,污染源任意位於河北省監測站所在位置。每個污染源每小時排放一個粒狀物。一個區域內的顆粒物數量越多,污染程度就越高(藍色對應低濃度,紅色~棕色對應高濃度)。風模型基於全球預報系統(又稱 GFS)。
--
Air Quality Forecast Viewer
version 1.2 (2016/2/18)
version 1.2 (2016/2/18)
Loading..
--
與需要超級電腦處理能力才能計算整個世界空氣品質預測的複雜模型相比,這當然是一個非常輕的模型。但它的優點是可以直觀地解釋空氣品質預測背後的基本概念。
更準確地說,模型應該包括垂直風廓線,以及幾個高度(層)的預報——目前,模型只使用10米、100米和5KM的預報。而且,污染源應該更全面,包括全世界的污染源──目前只包括河北省的污染源。
--
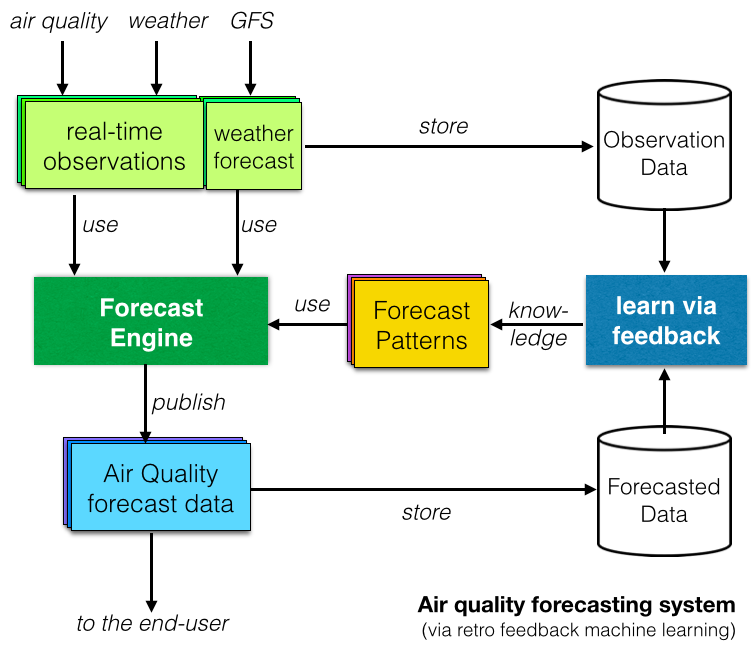
最後,許多研究報告調查了基於機器學習或人工智慧的空氣品質預測系統。背後的概念是透過將觀察到的數據與預測的數據進行比較來「學習」並識別重複模式(如右圖所示)。
在紙面上,基於機器學習的預測系統看起來不錯,但實際上,它們比傳統的確定性模型(我們在世界空氣品質指數專案中更喜歡傳統的確定性模型)更好嗎?參考Talithia Williams精彩的TED 演講“擁有你的身體數據”,我們對這個問題的回答是“向我們展示數據!”,這也是我們將在下一篇關於預測的文章中討論的內容!

