
Već smo dosta puta pisali o utjecaju vjetra na onečišćenje zraka, te kako jaki vjetrovi (točnije, jaka ventilacija ) mogu pomoći da se zrak očisti u vrlo kratkom vremenu. Ali nikada nismo imali priliku stvarati na dinamičkoj vizualizaciji ovog fenomena, pa će o tome pisati ovaj članak.
--
Što se tiče prognoze kvalitete zraka, ključ veće točnosti je doraditi model prognoze i izraditi specifičnu modelizaciju za svaku zemlju, a još bolje, za svaki grad. Na primjer, u Pekingu, blizina planina na sjeveru i Hebeija na jugu definira model:
- Južni vjetar ima tendenciju povećanja zagađenja u Pekingu: Ako vjetar nije dovoljno jak (tj. ne ventilira dovoljno), tada će čestice blokirati planine i neće se moći kretati dalje prema sjeveru, stvarajući tako gustu česticu koncentracija u Pekingu.
- Sjeverni vjetar nastoji očistiti onečišćenje: Kada vjetar dovoljno puše sa sjevera, zrak se gotovo odmah čisti jer na sjeveru nema "izvora onečišćenja" (ili, barem, mnogo manje nego na jugu).
To je ono što se može vidjeti na animaciji ispod, u kojoj su izvori onečišćenja proizvoljno smješteni tamo gdje se nalaze stanice za praćenje u Hebeiju. Svaki izvor onečišćenja emitira jednu česticu svakog sata. Što je veći broj čestica u zoni, veće je zagađenje (plavo odgovara niskim koncentracijama, crveno ~ smeđe visokim koncentracijama). Model vjetra temelji se na Globalnom sustavu prognoze (GFS).
--
version 1.2 (2016/2/18)
--
Ovo je naravno vrlo lagan model u usporedbi sa složenim modelima koji zahtijevaju super računalnu procesorsku snagu da bi mogli izračunati prognozu kvalitete zraka za cijeli svijet. Ali ima prednost što vizualno objašnjava osnovni koncept koji stoji iza predviđanja kvalitete zraka.
Točnije, model bi trebao sadržavati vertikalni profil vjetra, kao i prognozu za nekoliko visina (slojeva) – trenutno model koristi samo prognozu na 10 metara, 100 metara i 5KM. Štoviše, izvori onečišćenja trebali bi biti potpuniji i uključivati ukupne svjetske izvore - trenutno su uključeni samo izvori iz Hebeija.
--
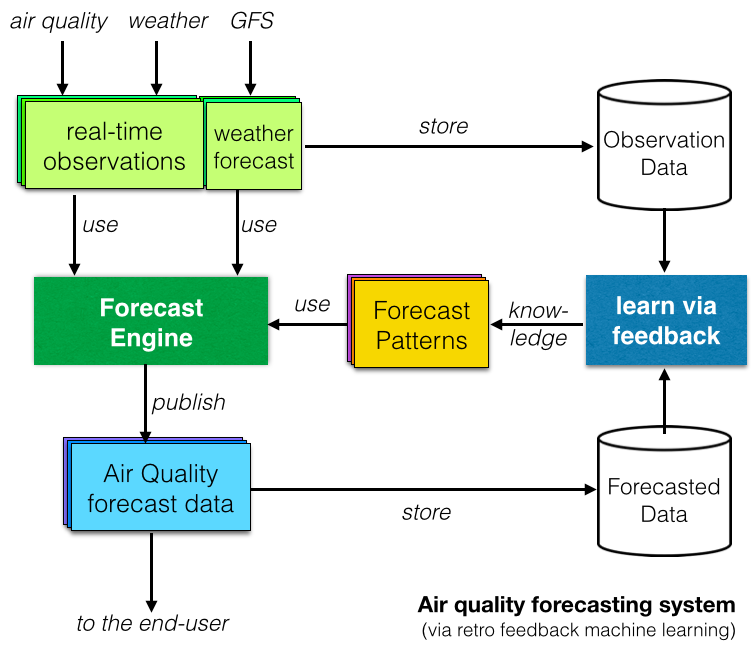
Na kraju, mnoga istraživačka izvješća istraživala su sustave predviđanja kvalitete zraka temeljene na strojnom učenju ili umjetnoj inteligenciji . Koncept iza je "učiti" usporedbom opaženih podataka s predviđenim podacima i identificirati ponavljajuće obrasce (kao što je prikazano na dijagramu s desne strane).
Na papiru, sustav predviđanja temeljen na strojnom učenju izgleda dobro, ali zapravo, jesu li bolji od tradicionalnih determinističkih modela (koje preferiramo u projektu Svjetskog indeksa kvalitete zraka )? Pozivajući se na izvrstan TED govor Talithie Williams o 'Posjedujte podatke o svom tijelu', naš odgovor na ovo pitanje je "pokažite nam podatke!", i to je nešto o čemu ćemo pisati u našem sljedećem članku o predviđanju!
