
我们已经写过好几次关于风对空气污染的影响,以及强风(或者更准确地说,强通风)如何有助于在很短的时间内净化空气。但我们从未有机会创建这种现象的动态可视化,所以这就是本文将要写的内容。
--
在空气质量预测方面,提高准确性的关键是完善预测模型,并为每个国家、甚至每个城市创建特定的模型。例如,在北京,北部的山脉和南部的河北的接近度定义了该模型:
- 南风往往会加剧北京的污染:如果风不够强(即通风不够),那么颗粒物就会被山脉阻挡,无法进一步向北移动,从而形成密集的颗粒物集中在北京。
- 北风往往能清除污染:当北风充分吹来时,空气几乎立即被清除,因为北方没有“污染源”(或者至少比南方少得多)。
如下动画所示,污染源任意位于河北省监测站所在位置。每个污染源每小时排放一个颗粒物。一个区域内的颗粒物数量越多,污染程度就越高(蓝色对应低浓度,红色~棕色对应高浓度)。风模型基于全球预报系统(又名 GFS)。
--
Air Quality Forecast Viewer
version 1.2 (2016/2/18)
version 1.2 (2016/2/18)
Loading..
--
与需要超级计算机处理能力才能计算整个世界空气质量预测的复杂模型相比,这当然是一个非常轻的模型。但它的优点是可以直观地解释空气质量预测背后的基本概念。
更准确地说,模型应该包括垂直风廓线,以及几个高度(层)的预报——目前,模型只使用10米、100米和5KM的预报。而且,污染源应该更全面,包括全世界的污染源——目前只包括河北省的污染源。
--
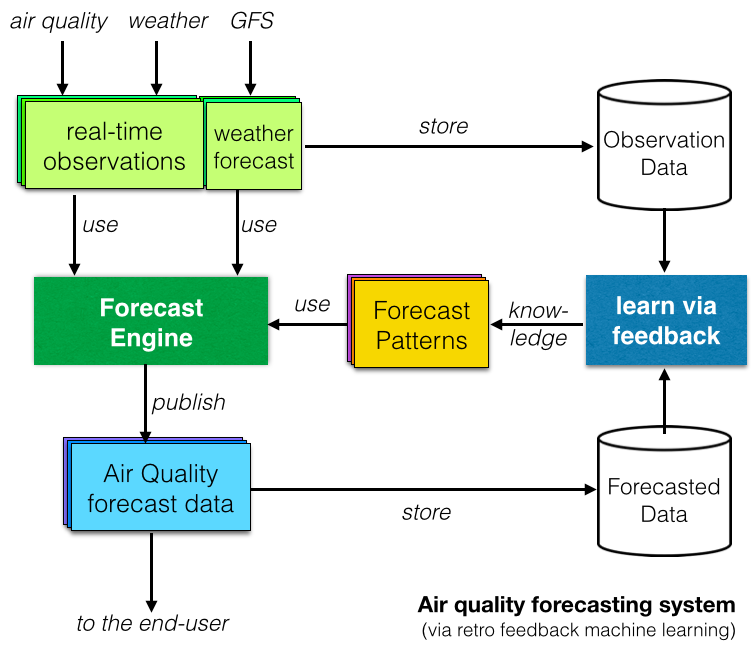
最后,许多研究报告调查了基于机器学习或人工智能的空气质量预测系统。背后的概念是通过将观察到的数据与预测的数据进行比较来“学习”并识别重复模式(如右图所示)。
在纸面上,基于机器学习的预测系统看起来不错,但实际上,它们比传统的确定性模型(我们在世界空气质量指数项目中更喜欢传统的确定性模型)更好吗?参考Talithia Williams精彩的TED 演讲“拥有你的身体数据”,我们对这个问题的回答是“向我们展示数据!”,这也是我们将在下一篇关于预测的文章中讨论的内容!
