
Писали сме доста пъти за влиянието на вятъра върху замърсяването на въздуха и как силните ветрове (или по-точно силната вентилация ) могат да помогнат за пречистване на въздуха за много кратко време. Но никога не сме имали възможността да създадем динамична визуализация на това явление, така че това е, за което тази статия ще пише.
--
Когато става въпрос за прогнозиране на качеството на въздуха, ключът към по-добра точност е усъвършенстването на модела за прогнозиране и създаването на специфично моделиране за всяка страна и, още по-добре, за всеки град. Например в Пекин близостта на планините на север и Хъбей на юг определя модела:
- Южният вятър има тенденция да увеличава замърсяването в Пекин: Ако вятърът не е достатъчно силен (т.е. не е достатъчно проветряващ ), тогава частиците ще бъдат блокирани от планините и няма да могат да се движат по-нататък на север, създавайки по този начин плътни частици концентрация в Пекин.
- Северният вятър има тенденция да изчиства замърсяването: Когато вятърът духа достатъчно от север, въздухът почти веднага се изчиства, тъй като на север няма „източник на замърсяване“ (или поне много по-малко, отколкото на юг).
Това може да се види в анимацията по-долу, в която източниците на замърсяване са произволно разположени там, където са разположени станциите за мониторинг в Хъбей. Всеки източник на замърсяване излъчва една частица на всеки час. Колкото по-голям е броят на частиците в една зона, толкова по-високо е замърсяването (синьото съответства на ниска концентрация, червено ~ кафяво на висока концентрация). Моделът на вятъра се основава на глобалната прогнозна система (известна още като GFS).
--
version 1.2 (2016/2/18)
--
Това, разбира се, е много лек модел в сравнение със сложните модели, които изискват супер мощ на компютърна обработка, за да могат да изчислят прогнозата за качеството на въздуха в целия свят. Но има предимството да обяснява визуално основната концепция зад прогнозирането на качеството на въздуха.
За да бъдем по-точни, моделът трябва да включва вертикален профил на вятъра, както и прогноза за няколко височини (слоеве) - в момента моделът използва прогноза само на 10 метра, 100 метра и 5KM. Освен това източниците на замърсяване трябва да бъдат по-пълни и да включват всички световни източници - в момента са включени само източници от Хъбей.
--
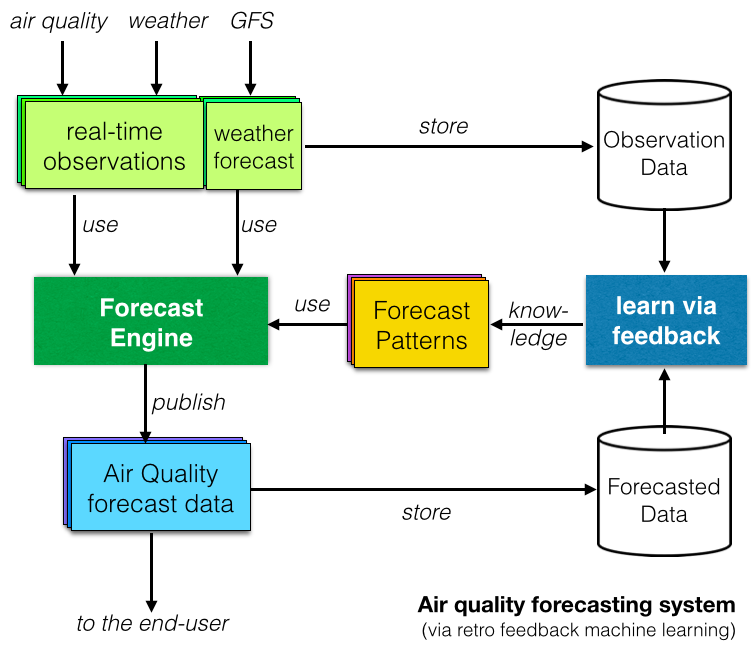
И накрая, много изследователски доклади са изследвали системи за прогнозиране на качеството на въздуха, базирани на машинно обучение или изкуствен интелект . Концепцията зад нея е да се „учи“ чрез сравняване на наблюдаваните данни с прогнозираните данни и идентифициране на повтарящи се модели (както е показано на диаграмата вдясно).
На хартия системата за прогнозиране, базирана на машинно обучение, изглежда добре, но в действителност по-добри ли са от традиционните детерминистични модели (които ние предпочитаме в проекта за Световния индекс на качеството на въздуха )? Позовавайки се на отличната лекция на TED от Талития Уилямс на тема „Притежавайте данните за тялото си“, нашият отговор на този въпрос е „покажете ни данните!“ и това е нещо, за което ще пишем в следващата ни статия за прогнозиране!
