
Himalayan Mountains seen from Space
पिछले महीनों के दौरान, विश्व वायु गुणवत्ता टीम कई नए वायु गुणवत्ता पूर्वानुमान मॉडलों का विश्लेषण करने के साथ-साथ वायु गुणवत्ता पूर्वानुमान मॉडल प्रदर्शक में सुधार करने पर काम कर रही है।
यह लेख नवीनतम पूर्वानुमान मॉडल प्रदर्शक प्रस्तुत करेगा, जो विश्व की ग्रिडेड जनसंख्या ( जीपीडब्ल्यू ) पर आधारित है, और जिसे उत्तरी भारत क्षेत्र (बांग्लादेश, पाकिस्तान और नेपाल सहित) के लिए वायु गुणवत्ता पूर्वानुमान का विश्लेषण करने के लिए लागू किया जाएगा।
--
पूर्वानुमान मॉडल और गणना अभी भी जीएफएस पवन पूर्वानुमान पर आधारित है, जैसा कि हमने बीजिंग क्षेत्र में पूर्वानुमान के बारे में पिछले लेख में दर्शाया था कि वायु गुणवत्ता पूर्वानुमान के लिए हवा एक आवश्यक घटक है।
हालाँकि, पिछले सिमुलेशन के विपरीत जहां प्रदूषण स्रोत मनमाने ढंग से हेबेई क्षेत्र में विशिष्ट स्थानों पर स्थित थे, इस उत्तरी भारत के पूर्वानुमान के लिए इस्तेमाल किया गया मॉडल कोलंबिया विश्वविद्यालय CIESIN से विश्व की ग्रिडेड जनसंख्या (उर्फ GPW 2015 ) पर आधारित है। [1] :
धारणा यह है कि किसी दिए गए क्षेत्र में रहने वाले लोगों की संख्या जितनी अधिक होगी, मानवजनित प्रदूषण उत्पन्न होने की संभावना उतनी ही अधिक होगी।
यह वास्तव में 100% सही धारणा नहीं है क्योंकि भारी उद्योगों द्वारा उत्पन्न प्रदूषण जनसंख्या द्वारा उत्पन्न प्रदूषण से कहीं अधिक हो सकता है, लेकिन हम अपने अगले लेख में इस पर चर्चा करेंगे। इसलिए, इस लेख के लिए, जनसंख्या घनत्व और प्रदूषण एकाग्रता के बीच सहसंबंध की धारणा के तहत प्रदूषण पर हवा के प्रभाव को सत्यापित करना आवश्यक है।
--
नीचे दी गई छवि सिमुलेशन के लिए उपयोग किए गए घनत्व मॉडल (0.2° रिज़ॉल्यूशन पर) को दिखा रही है। इस ग्रिड मानचित्र पर प्रत्येक "पिक्सेल", या बिंदु को प्रदूषण स्रोत माना जाता है। हरे रंग का उपयोग कम घनत्व वाले क्षेत्रों के लिए किया जाता है, जो बहुत कम मात्रा में प्रदूषण उत्पन्न कर रहे हैं, जबकि गहरे रंग उन क्षेत्रों का प्रतिनिधित्व करते हैं जहां जनसंख्या और उत्पन्न प्रदूषण दोनों अधिक हैं।
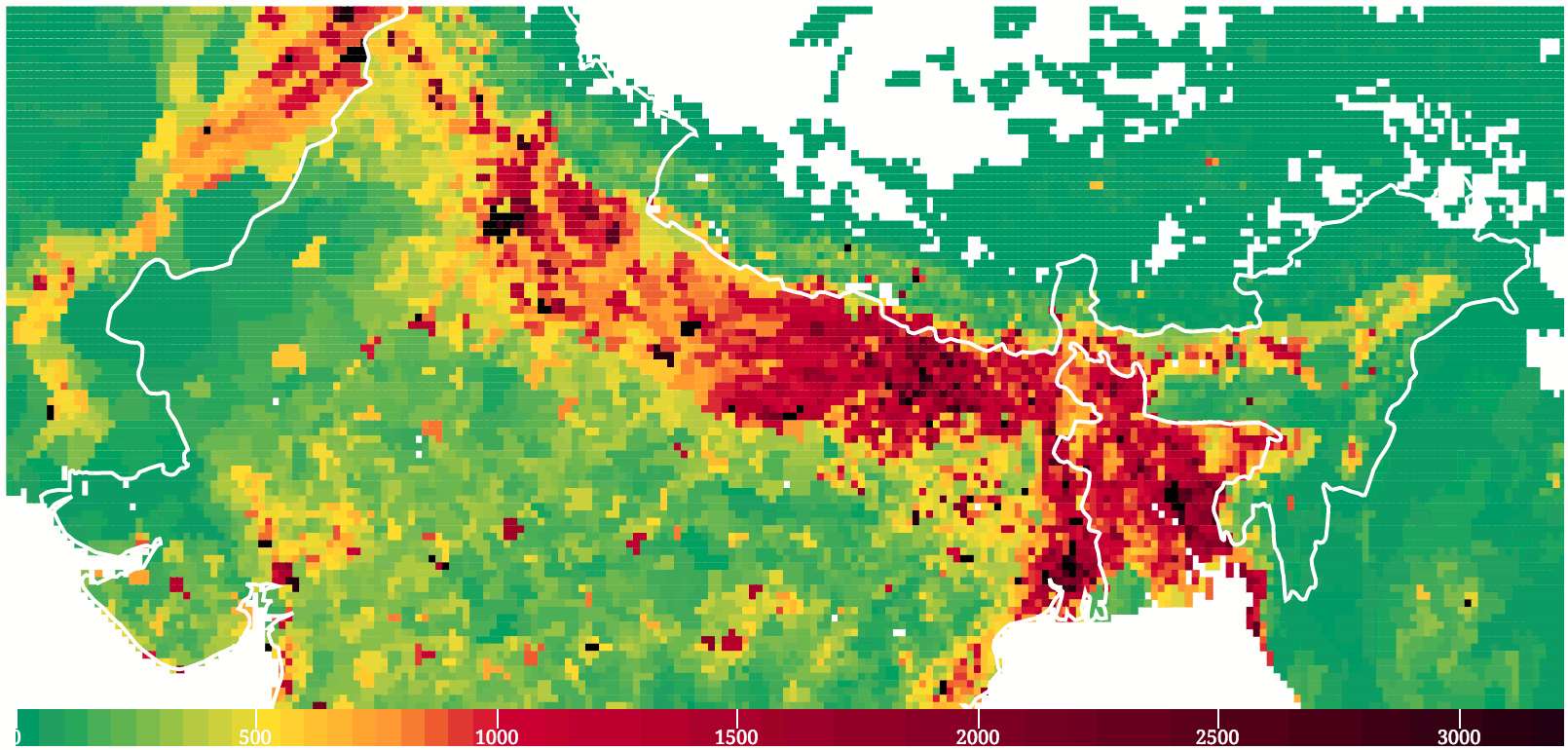
Population Density (persons per square meter)
नीचे दिया गया एनीमेशन वास्तविक [2] पवन डेटा के आधार पर वास्तविक समय की सांद्रता दिखा रहा है। ध्यान दें कि रंग कोडिंग और संबंधित एकाग्रता का स्तर मनमाना है - और आगे के काम के बिना एक-से-एक AQI स्तर से जुड़ा नहीं हो सकता (और नहीं होना चाहिए)। आवश्यक विचार यह है कि हवा की स्थिति के पूर्वानुमान के आधार पर उन क्षेत्रों की रूपरेखा तैयार की जाए जिनमें उच्च या बहुत अधिक प्रदूषक सांद्रता होने की संभावना है।
--
-
--
बहुत अधिक आश्चर्य के बिना, नई दिल्ली में उच्च स्तर का प्रदूषण संकेंद्रण देखा जा रहा है, लेकिन जो वास्तव में दिलचस्प है वह बीजिंग की तुलना में नई दिल्ली की स्थिति की तुलना करना है: बीजिंग में, निकट उत्तर में वस्तुतः कोई मानवजनित प्रदूषण नहीं है, इसलिए, जब हवा उत्तर से चलती है तो हवा तुरंत साफ हो जाती है। लेकिन नई दिल्ली के लिए उत्तर में जनसंख्या घनत्व अभी भी काफी अधिक है, इसलिए उत्तर से तत्काल स्वच्छ हवा मिलने की संभावना बहुत कम है। क्रमबद्ध शब्दों में, नई दिल्ली को अपनी हवा को साफ़ करने के लिए बहुत अधिक मात्रा में वेंटिलेशन (या संचयी पवन ऊर्जा) की आवश्यकता होती है।
दूसरा अवलोकन बांग्लादेश की स्थिति है: उपरोक्त अनुकरण से, पूर्व और उत्तर में पहाड़ों की निकटता के कारण प्रदूषण स्पष्ट रूप से बांग्लादेश में फंस रहा है। यह वास्तव में ढाका में रहने वाले किसी भी व्यक्ति के लिए आश्चर्य की बात नहीं है।
दुर्भाग्य से, लेखन के समय वास्तव में बांग्लादेश/ढाका में कोई निगरानी स्टेशन उपलब्ध नहीं है, इसलिए पूर्वानुमान सटीकता बनाम वास्तविक टिप्पणियों को सत्यापित करना संभव नहीं है।
(नोट: इस लेख के लिखे जाने के कुछ दिनों बाद, ढाका में अमेरिकी सलाहकार ने अपना वायु गुणवत्ता डेटा प्रकाशित करना शुरू कर दिया, जिसे आप इस लिंक से पा सकते हैं: शहर/बांग्लादेश/ढाका/हमें-वाणिज्य दूतावास )।
बांग्लादेश में वायु गुणवत्ता के बारे में अधिक जानकारी के लिए, आप इस पृष्ठ को देख सकते हैं: देश/बांग्लादेश/ ।
--
निष्कर्ष के रूप में, यह पूर्वानुमान मॉडल अभी भी पूरा होने से बहुत दूर है, लेकिन कम से कम, उत्तरी भारत में प्रदूषण की सघनता पर हवा के प्रभाव को दिखाने में इसका फायदा है, और विशेष रूप से हिमालय के पहाड़ वायु प्रदूषण को कैसे रोक रहे हैं। अगले संस्करण में, हम ज्ञात सकारात्मक प्रवाह को ध्यान में रखते हुए प्रदूषण स्रोतों के लिए एक उन्नत संस्करण पेश करेंगे, जिसे हम अवलोकनों से घटा सकते हैं।
--
नोट: वास्तविक समय पूर्वानुमान दर्शक को इतने विस्तृत क्षेत्र को संभालने में सक्षम बनाने के लिए, हमारी टीम को कुछ सुधारों और अनुकूलन पर कड़ी मेहनत करनी पड़ी। अब हम 10K से अधिक कणों को संभालने में सक्षम एक और भी अधिक अनुकूलित संस्करण पर काम कर रहे हैं, और हम इसके कोड को खुला स्रोत बनाने पर विचार कर रहे हैं, इसलिए यदि आप रुचि रखते हैं, तो नीचे "चर्चा" बोर्ड के माध्यम से हमें एक संदेश भेजें (हम केवल ऐसा करेंगे) इसे ओपन सोर्स तभी बनाएं जब इसकी पर्याप्त मांग हो)।
